1. Redis와 Memcached
In-memory Database를 검색하면 다양한 제품들이 존재하지만, 여러 회사에서 사용 중이고 유명한 두가지는 Redis와 Memcached입니다.
이유는 오픈소스(무료)에 속도가 빠르며, Key-Value를 한 쌍으로 데이터를 저장하기 때문입니다.

현재 진행 중인 프로젝트에서 Key와 Value로 저장하는 방식이 세션을 다루기 적합할것이라 생각해 Redis와 Memcached 중 하나를 선택하기로 했습니다.
2. Redis와 Memcached의 비교
Collection 구조
Redis는 기본적으로 Collection 구조를 제공합니다.
그래서 개발시 편리하고, 개발 시간을 단축할 수 있다는 장점이 있지만, 잘못된 Collection을 사용하면 데이터를 다룰 때 속도에 영향을 줄 수 있으니 주의해서 사용해야 합니다.
하나의 컬렉션에 너무 많은 아이템을 넣으면 조회시 시간이 오래걸리므로 1만개 이하로 유지하는 것이 좋다고 합니다.
하지만 Memcached는 다양한 구조를 제공하지 않고 String만 지원합니다.
장애에 대한 처리
In-memory Database의 경우 메모리 용량이 부족하여 더이상 데이터를 저장하지 못하거나, 장애가 생겨 서버가 중단되는 경우 기존의 데이터가 사라질 수 있습니다.
그에 대비해 Redis는 장애를 위한 Replication(복제) 기능을 제공합니다.
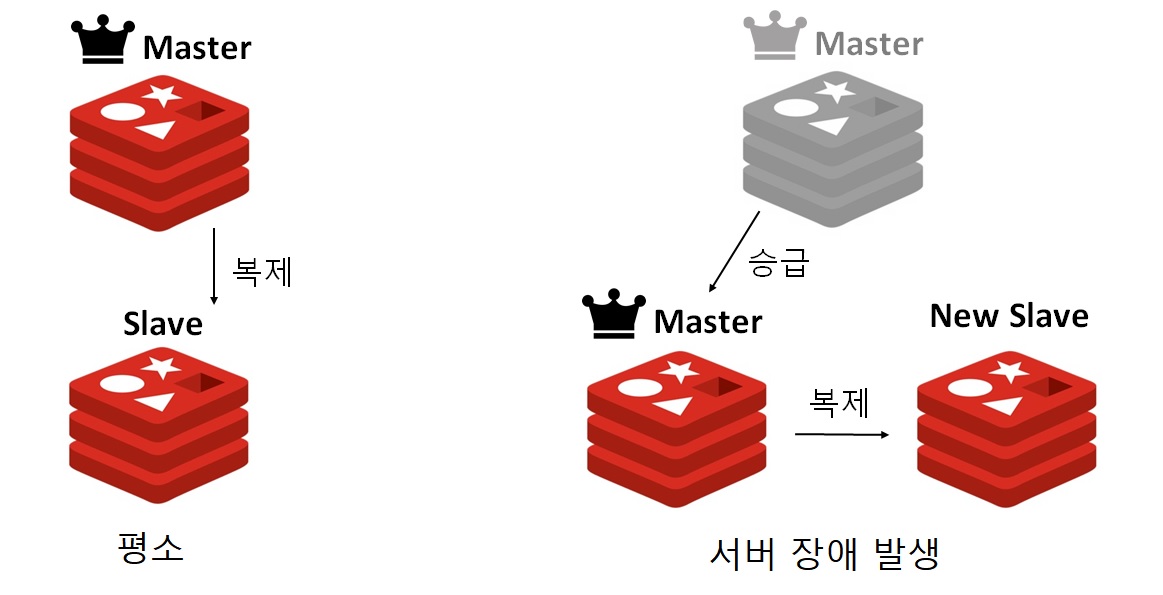
복제 기능을 이용하여 Master-Slave 기능을 사용할 수 있게되는데, Master(주)와 Slave(종)가 나뉘어져 Master에 처음 모든 데이터를 저장하고, Slave에 같은 데이터를 복제하여 저장합니다. Master는 읽기, 쓰기가 가능하고, Slave는 데이터만 읽을 수 있는데, 이후 Master에 문제가 생길 경우 Slave는 에러를 발생시키고, Slave가 Master로 변해 서비스를 이어갈 수 있게 됩니다.
하지만 여기서 한가지 단점이 있는데, 복제 과정이 비동기라는 것입니다. 만약 복제가 제대로 종료되지 않았더라도, Master는 그에 대해 기다리지 않기 때문에 복제 도중 Master에 장애가 일어날 경우 Slave가 모든 데이터를 가지고 있지 않을 수 있다는 점도 생각해야 합니다.
반면, Memcached는 Consistent Hashing 알고리즘을 통해 여러 Memcached 서버에 데이터를 분산 저장하는 기능을 제공합니다. Memcached 서버의 수가 늘어날 수록 손실되는 데이터의 수는 줄겠지만 결론적으로 장애가 일어난 곳의 데이터는 사용할 수 없으니 장애를 완전하게 극복하지는 못합니다.
이를 대비하여 각 Memcached 서버마다 백업 서버를 배치하는 경우도 있지만, 금전적인 문제도 생각해봐야 할것같습니다..
참고! 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 특성을 영속성 persistence라 합니다.
thread
Redis는 싱글 스레드, Memcached는 멀티스레드로 작동합니다.
마치 두 결과값이 큰 차이를 보일수 있다고 생각할 수 있지만, 결론부터 말하자면 둘 모두 결과값을 보장할 수 있습니다.
왜냐하면 Memcached의 경우 명령어를 파싱하는 부분까지는 멀티스레드로 수행하지만, 데이터에 접근하는 경우에는 싱글스레드처럼 동작하기 때문입니다.
또, Redis는 싱글스레드이기 때문에 병목현상이 발생해 속도가 느려지지 않을까? 라는 생각이 들 수도 있지만, 메모리에서 빠르게 동작하기 때문에 병목현상이 일어날 일이 적다고 합니다.
파이프라인을 이요하면 초당 100만건의 요청을 처리할 수 있다고 합니다.
Memcached는 멀티스레드를 제공하지만, 그렇다고 너무 많은 스레드를 사용할 경우 성능이 저하될 수 있으니 주의해서 사용해야합니다.
응답 속도
둘 모두 기본적으로 빠르긴 하지만 상황에 따라 속도가 달라지기도 합니다. Redis의 경우 대규모 트래픽이 들어올 경우 속도가 변할 수 있습니다. 왜냐하면 jemalloc 알고리즘을 사용하여 malloc과 free를 통해 메모리를 할당하는 작업을 반복하기 때문에 대규모 트래픽이 발생하게 되면 응답 속도가 느려질 수도 있습니다.
게다가 Redis는 메모리가 부족하면 디스크에도 데이터를 저장하게 되는데, 한번 디스크에 저장된 데이터는 접근할 때마다 Swap이 일어나 속도가 느려지기도 합니다.
Swap : 메모리가 부족할 때 메모리의 내용을 디스크에 저장한 후 필요시 디스크에 접근하여 다시 메모리로 끌어올리는 작업. 디스크와 메모리간의 교환
반면 Memcached의 경우 메모리를 다시 할당하지 않기때문에 느려지지는 않고, 메모리가 부족하다는 이유로 디스크까지 이용하여 저장하지 않기 때문에 메모리 부족으로 느려지는 일은 없습니다.
하지만 메모리가 부족할 경우 가장 적게 사용한 데이터들부터 삭제하여 메모리를 마련하기 때문에 오히려 데이터가 사라진다는 것을 조심해야 합니다.
3. 결론
트래픽이 늘어나 서버를 확장시킬 경우 어떻게 여러대의 서버의 데이터 불일치를 해결할까? 에 대한 고민을 하면서 가장 중요하게 생각했던 것은 데이터 손실이 없고, 그로인한 서비스 중단도 없어야 한다는 것입니다.
그래서 최종적으로 결정한 것은 Redis입니다.
Redis와 Memcached를 비교했을 때 상대적으로 데이터 손실이 적으며, 장애가 발생했을 때 대처하는 방법도 있기 때문입니다. 또한, 사용중인 스프링 부트에서는 Redis를 지원하고 있기 때문에 편리하게 사용할 수 있다는 점도 장점이었습니다.
이렇게 3편에 이어진 긴 글이었지만 다중 서버 환경에서 세션을 관리할 수 있게 하는 방법에 대하여 알 수 있게되었고, 우리의 프로젝트에 사용할 해결법을 찾을 수 있게 되었습니다!
참고
- Redis 홈페이지
- Memchached 홈페이지
- 우아한 테크 세미나 - 우아한 레디스 by 강대명 님
- Comparing Redis and Memcached, AWS
- 개발자를 위한 레디스 튜토리얼, GARIMOO
관련 프로젝트
- event-recommender-festa (2020-09 ~)