1. 데이터 불일치를 해결하는 방법
이전 글에서 사용자가 늘어 서버가 감당할 수 없는 양의 트래픽이 발생할 경우를 대비하여 Scale-out 방식으로 서버를 늘려 프로젝트를 진행하기로 했습니다.
하지만 Scale-out의 경우 서버가 여러대이기 때문에 서버 간 데이터가 일치하지 않는 현상을 처리해야 합니다.
대표적으로 로그인을 예시로 들어보자면, 로그인 시 Session을 생성하여 서버에 저장하고, 해당 세션을 이용하여 사용자가 로그인 상태임을 알 수 있습니다.
그런데 서버가 여러개인 경우 로그인했던 서버가 아닌 다른 서버로 다시 요청을 하면 다른 서버에는 Session이 없기 때문에 로그인 상태에서 벗어나버린다는 문제가 생깁니다.
이 때 사용하는 방법이 Sticky Session과 Session Clustering, In-MemoryDB입니다.
2. Sticky Session
Sticky Session은 처음 요청을 보냈을 때 응답을 준 서버로만 계속 요청을 보내, 특정 서버에 붙어있는 방식입니다.
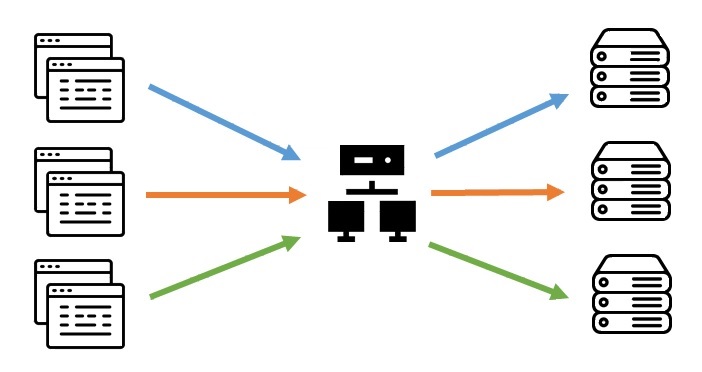
그림에서 보듯 첫번째 요청은 계속 첫번째 서버로만, 두번째 요청은 두번째 서버로만 전달되고 있습니다.
이렇게 특정 서버로만 요청을 하기 때문에 세션이 그대로 있어 데이터 불일치 문제를 해결할 수 있지만, 또 다른 단점도 있습니다.
- 서버 하나로만 많은 요청이 몰릴 수 있습니다.
- 자신의 세션이 없는 다른 서버는 사용할 수 없습니다.
- 하나의 서버에 장애가 발생한다면, 해당 서버에 있는 세션들을 모두 사용할 수 없습니다.
첫번째 단점인 ‘서버 하나로만 많은 요청이 몰릴 수 있다’는 점은 어떤 일에서 벌어질까요?
예를들어 1, 2, 3번 서버에 세션이 골고루 저장되었지만, 2, 3번의 사용자들은 금방 로그아웃을 하여 사용을 그만두는 반면, 1번 서버의 사용자들만 유독 오랫동안 연결을 유지하며 요청을 계속하는 경우가 있을 수 있습니다.
그 외에도 외부 IP는 모두 같지만, 내부 IP는 다른 여러 기기가 있습니다. 작게보면 집안에서 핸드폰, 컴퓨터, 패드가 모두 같은 와이파이를 이용하여 외부 IP는 같지만 내부 IP는 다른상황일 수도 있고, 크게보면 회사에서 모두 같은 외부 IP를 사용하지만 내부 IP는 다른 컴퓨터가 여러대 있는 상황일 수도 있습니다. 이럴 때 Load Balancer는 같은 IP로 들어오는 요청을 하나의 서버로만 보내기 때문에 겉보기에는 하나의 기기가 요청한것처럼 보이나 실제로 속에서는 여러 기기의 요청이 있기 때문에 하나의 서버로만 요청이 몰리는 경우가 오게됩니다.
세번째 단점인 ‘하나의 서버에 장애가 발생한다면, 해당 서버에 있는 세션들을 모두 사용할 수 없다’는 우리가 Scale-out을 선택한 이유와는 어울리지 않는 단점입니다.
이전 글에서 Scale-out을 선택한 이유 중 하나가 “서버에 문제가 생기더라도 사용자는 서비스를 불편 없이 이용할수 있었으면 좋겠다.” 였는데, 서버에 장애가 생길 경우 장애가 생긴 서버를 이용하는 사용자들이 로그인이 끊기는 불편함을 겪을 것이기 때문에 우리가 원하는 방식이 아닙니다.
참고!
위의 그림 중앙에 요청을 각 서버로 분배해주는 일을 하는 것을 Load Balancer라고 부르고, Load Balancer는 요청한 브라우저에 쿠키를 생성하여, 해당 쿠키를 이용하여 각 서버로 요청을 전달해주는 일을 합니다.
3. Session Clustering
Session Clustering은 여러 서버가 하나처럼 작동하도록 하는 기술입니다.
Sticky Session과는 다르게 여러 서버를 하나로 묶어 사용하기 때문에 일부 서버에 장애가 생기더라도, 다른 서버들이 있어 문제가 생기지 않습니다.
Session Clustering은 사용하는 WAS에 따라 다른 방법이 적용되기 때문에 사용하는 WAS를 살펴봐야합니다.
현재 진행중인 프로젝트는 스프링 부트로 진행중이며, 스프링부트는 Tomcat을 내장중이기 때문에 Tomcat의 Session Clustering 방법을 찾아봐야 합니다.
참고!
사용 중인 스프링 부트는 2.3.4 버전이고, 해당 버전은 Tomcat 9.0.38을 사용중입니다.(2020-10-23 기준)
본인의 Tomcat 버전을 알고 싶다면 mvnrepository.com에서 확인하거나, 더 정확히 알고싶다면 진행중인 프로젝트의 외부 라이브러리 목록을 확인하면 됩니다.
3-1. all-to-all
Tomcat9의 Session Clustering 문서를 보면 가장 처음 나와있는 방법인데, Delta Manager를 사용하여 특정 노드에서 발생한 Session 정보를 나머지 모든 노드에 복제하는 방식입니다.
이렇게 하면 어떤 서버로 요청을 해도 모든 세션을 가지고 있기 때문에 데이터 불일치 문제를 해결할 수 있고, 한 서버에 장애가 생기더라도 다른 서버가 작동 중이기 때문에 장애문제도 해결할 수 있습니다.
하지만 이 방법에도 단점은 존재하는데,
- 모든 데이터를 각 노드에 저장해야 하고, 배포용 노드가 아닌 경우에도 복제되기 때문에 메모리 문제가 발생합니다.
- 세션 데이터가 저장될 때마다 모든 서버에 똑같은 값을 저장해주어야 하므로 서버 수가 많아질수록 성능 저하가 발생해 서버가 4개 이상인 경우에는 권장하지 않고 있습니다.
Scale-out 방식을 사용하려는 이유 중 하나가 메모리 문제인데.. all-to-all방식은 모든 세션 데이터를 모든 서버에 저장하고 있으니 여전히 메모리 문제가 발생합니다.
또 세션이 생성될 때마다 모든 서버에 값을 저장해 주어야 하기 때문에 이로인한 트래픽 증가 문제가 있기 때문에 이 또한 우리가 원하는 방법이 아니었으니, 다음으로 넘어가봅니다.
3-2. Primary-secondary
이 방법은 Backup Manager를 사용하여 특정 노드에서 발생한 세션 정보를 나머지 하나의 노드에만 복제하여, 총 두개의 노드에만 세션을 가지고 있는 방법입니다.
순서는 아래와 같습니다.
- 요청이 들어오면 로드밸런서에 의해 선택된 서버가 세션을 생성하고, 해당 서버는 Primary node가 된다.
- 그 후 다른 서버 중 하나가 Primary node의 데이터를 복제하여 Backup node가 된다.
- 나머지 서버들은 Primary와 secondory node의 주소와 key만 복제되어서 Proxy node가 된다.
여기서 Proxy node는 세션 key와 Primary node, Backup node의 주소를 저장하고 있어서 Proxy node로 요청이 들어올 경우 Proxy는 가지고 있는 Primary node의 주소를 이용해 Primary node에 해당하는 세션 데이터를 요청하여 데이터 불일치 문제를 해결합니다.
데이터 불일치 문제를 해결했으니 장애문제를 살펴보면, Primary node에 장애가 생길 경우 Backup node가 Primary node로 변하여 또 다른 Backup node를 만들어내 장애 문제를 해결해줍니다. (반대의 경우도 마찬가지)
하지만 해당 방식은
- Proxy 서버에 요청이 들어오면 다시 Primary 서버에 요청을 하여 Key에 대한 값을 받아와야 한다.
- 계속해서 복제가 일어난다.
같은 단점이 있습니다.
4. In-memory Database
In-memory Database는 HDD나 SSD가 아닌 주기억장치(RAM)에 저장되는 데이터베이스로, 기존의 방식들과는 다르게 세션 저장소를 따로 분리해서 사용하는 것입니다.
디스크가 아닌 메모리에 저장되기 때문에 데이터 접근시 더 빠르지만, 휘발성 데이터이기 때문에 컴퓨터의 전원이 꺼지면 데이터가 사라질 수 있습니다. 그래서 In-memory Database는 중요한 데이터 대신, 세션처럼 사라져도 상관 없는 임시 데이터를 저장하는데 주로 사용됩니다.
로그파일을 이용하여 휘발성 문제를 해결할 수도 있고, 최근에는 비 휘발성 RAM 기술로 서버가 종료되더라도 데이터를 유지할 수 있는 경우도 있다고 합니다.
In-memory Database의 경우 서버의 저장소를 사용하는 것이 아닌 분리된 세션 저장소를 사용하기 때문에, WAS에 장애가 생기더라도 서비스를 계속 제공할 수 있고, 세션도 하나이기 때문에 데이터 불일치에 대한 문제와 데이터의 복사로 인한 성능 저하도 해결할 수 있습니다.
5. 어떤 방법을 사용할까?
여태동안 데이터 불일치 문제를 해결하기 위해 Stick Session, Session Clustering, In-memory Database 세가지 방법을 살펴보았습니다.
그리고 여러 장단점을 살펴본 결과..
- 데이터 불일치를 해결할 수 있다.
- 계속되는 세션 복제로 인한 성능 저하를 해결할 수 있다.
- WAS에 장애가 있어도 세션을 계속 제공할 수 있다.
- 데이터에 접근하는 시간이 빠르다.
와 같은 장점이 있는 In-memory Database를 사용하기로 했습니다.
In-memory Database에도 여러 종류가 있는데, 오픈소스(무료)면서 유명한 제품은 Redis와 Memcached가 있고, 둘 중 어떤 제품을 사용할지는 둘의 장단점을 비교해보며 생각해 봐야겠습니다.
Redis와 Memcached의 비교는 다음 글에서 진행됩니다.
참고
다음 글
관련 프로젝트
- event-recommender-festa (2020-09 ~)