1. Consistent Hashing?
이전 글 중 Redis와 Memcached를 비교하는 글에서 ‘Memcached는 Consistent Hashing 알고리즘을 통해 여러 Memcached 서버에 데이터를 분산 저장하는 기능을 제공합니다’라는 문장을 사용했습니다.
여기서 Consistent Hashing이 어떤것일까요?
Consistent Hashing은 분산 처리 환경에서 사용하는 알고리즘입니다. 서버가 여러개일 때 Load Balancer가 클라이언트들을 어느 서버로 보내주어야할 지 정할 때 사용하는데요, 이 알고리즘의 특징은 해시함수와 원입니다.
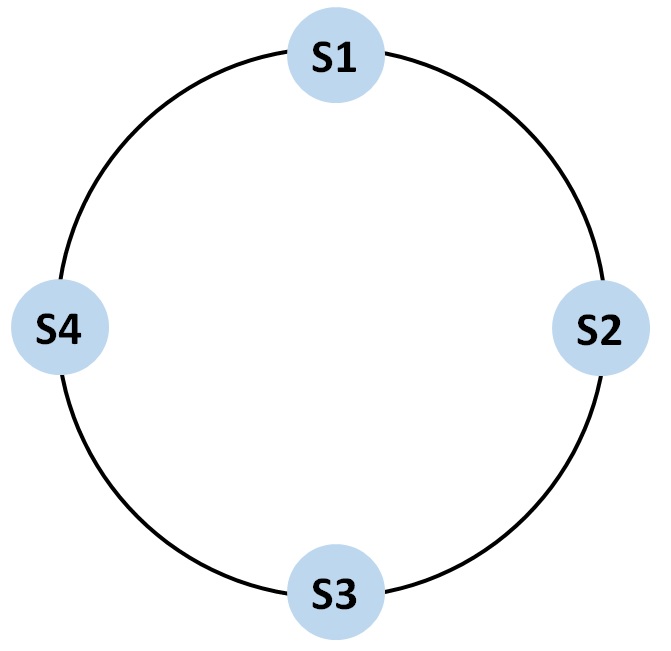
일단 서버 4개를 원 위에 올려둡니다. 이제 여러 클라이언트가 서버에 요청을 하면 4개의 서버 중 적절하게 나눠주어야 합니다.
시계처럼 생각해봅시다. 서버1 즉 S1은 12입니다. S2는 3, S3은 6, S4는 9를 가진다고 생각해봅시다.
이제 여러 클라이언트가 요청을 보내고, 처음 요청한 서버에 딱 달라붙어 해당 서버로만 요청을 보내도록 설정해주어야 합니다.
이때 Consistent Hashing은 이름처럼 해시함수를 이용하여 연결시켜줄 서버를 골라줍니다.
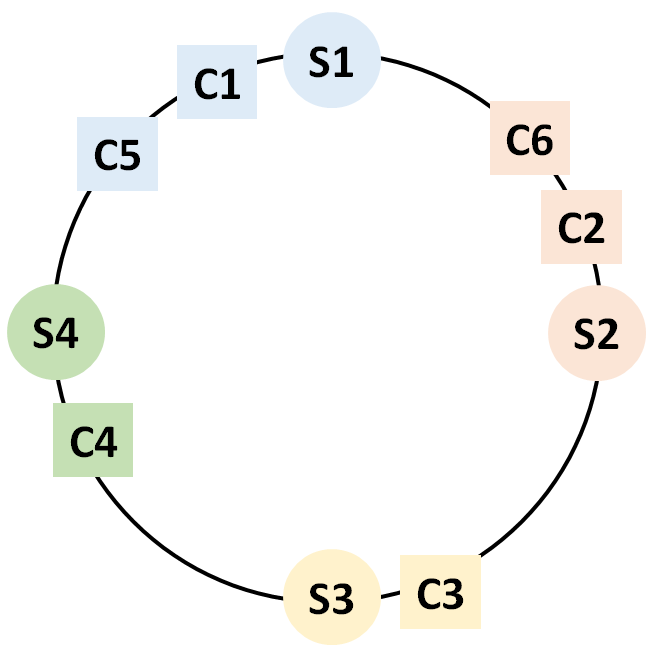
해시함수를 이용하여 나온 값으로 클라이언트 1부터 6을 각 위치에 두었습니다.
이제 각 클라이언트를 자신보다 큰 숫자를 가진 서버 중 가장 가까운 서버와 연결해줍니다.
C1, C5는 9부터 12사이에 있으니 자신보다 크면서 가장 가까운 위치에 있는 S1과 연결합니다. 다른 클라이언트들도 마찬가지로 서버와 연결합니다.
여기서 쉽게 이해하기 위하여 시계처럼 1부터 12에 서버와 클라이언트를 두었는데, 실제로는 각 클라이언트의 IP나 그의 해시키를 서버의 수로 나눈 나머지를 이용하여 서버와 연결한다고 합니다.
2. Consistent Hashing을 이용하던 중 서버에 장애가 발생하면?!
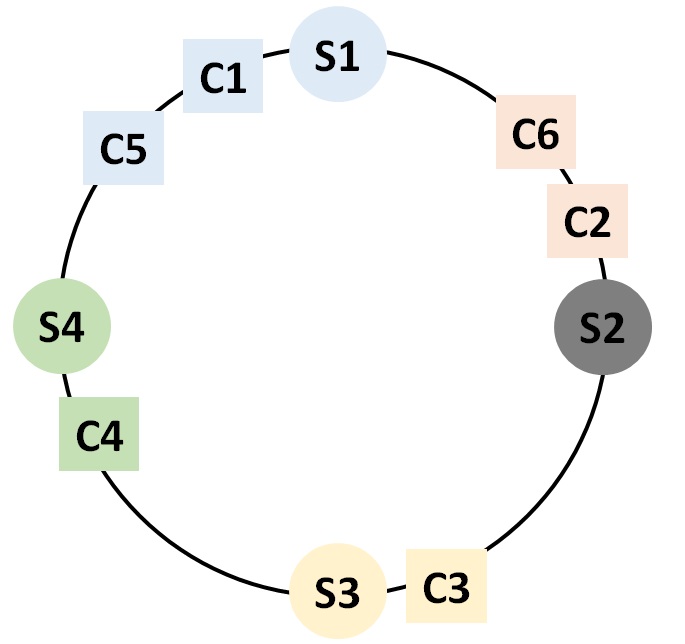
Consistent Hashing 알고리즘을 이용하여 각 서버와 클라이언트들을 연결해주었는데, S2가 장애가 발생하여 통신을 할 수 없는 상황이 되었습니다.
이럴 경우 어떻게 해야할까요?
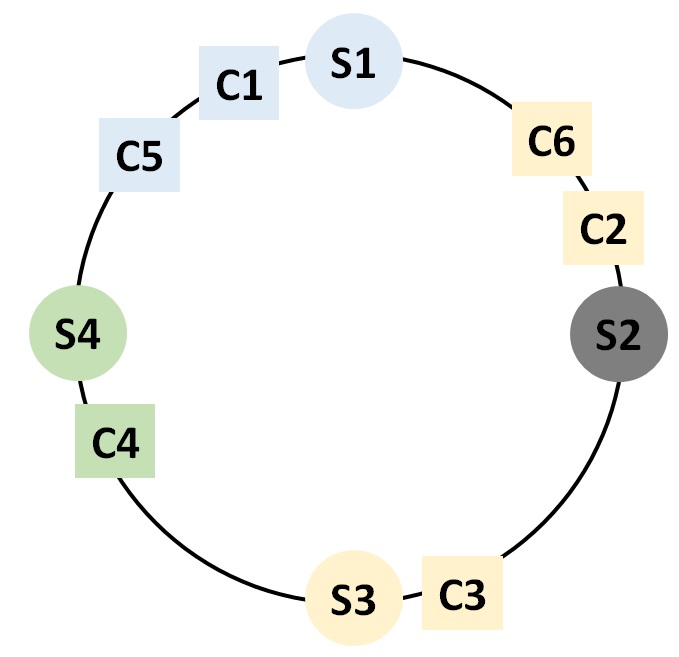
서버에 장애가 생긴다면 장애가 일어난 서버와 연결되어 있는 클라이언트들만 다시 재분배 해주면 됩니다. C2와 C6는 다음 서버인 S3과 연결이 됩니다.
그리고 이후 S2가 복구된다면 해시키를 이용하여 C2와 C6은 다시 S2와 연결됩니다.
Memcached에서의 장애
위에서 서버에 장애가 생기면 해당 서버와 연결된 클라이언트들만 다른 서버로 연결해주면 된다고 알아보았습니다.
그런데 추가로 더 살펴봐야할 것이 있습니다. 만약 위에서 S들이 Memcached 서버일 경우입니다.
Memecached 서버 S2에 장애가 생긴 후 복구하였지만, 또다시 장애가 생겼습니다. 그러면 C2와 C6은 다시 자동으로 S3과 연결될것입니다.
그리고 C2와 C6은 S2에 어떤 값을 요청합니다. S3는 C2와 C6가 요청한 값을 내어주었습니다.
여기서 문제는 S3에 ‘Old Data가 남아있을때’ 입니다.
만약 이전에 S2에 장애가 생겼을때 S3에 생긴 데이터가 사라지지 않고 이후에도 남아있게 된다면 S2의 재장애로 S3에 다시 연결되었을 때 S3가 옛날 데이터를 줄 수 있다는 것입니다.
물론 이 경우는 Memcached를 제대로 사용한다면 키가 자동으로 만료되어 해결되는 문제이기는 합니다.
기본만료시간은 10800초, 3시간입니다.
참고
- Consistent Hashing: Explained by The MemCachier Team
- Consistent hashing by Michael Nielsen
- Memcached 에서의 Consistent Hashing by charsyam
- How Consistent Hashing Is Used by Load Balancers to Distribute Requests by Zeng Hou Lim
블로그 내 관련 글
관련 프로젝트
- event-recommender-festa (2020-09 ~)